publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- arXiv
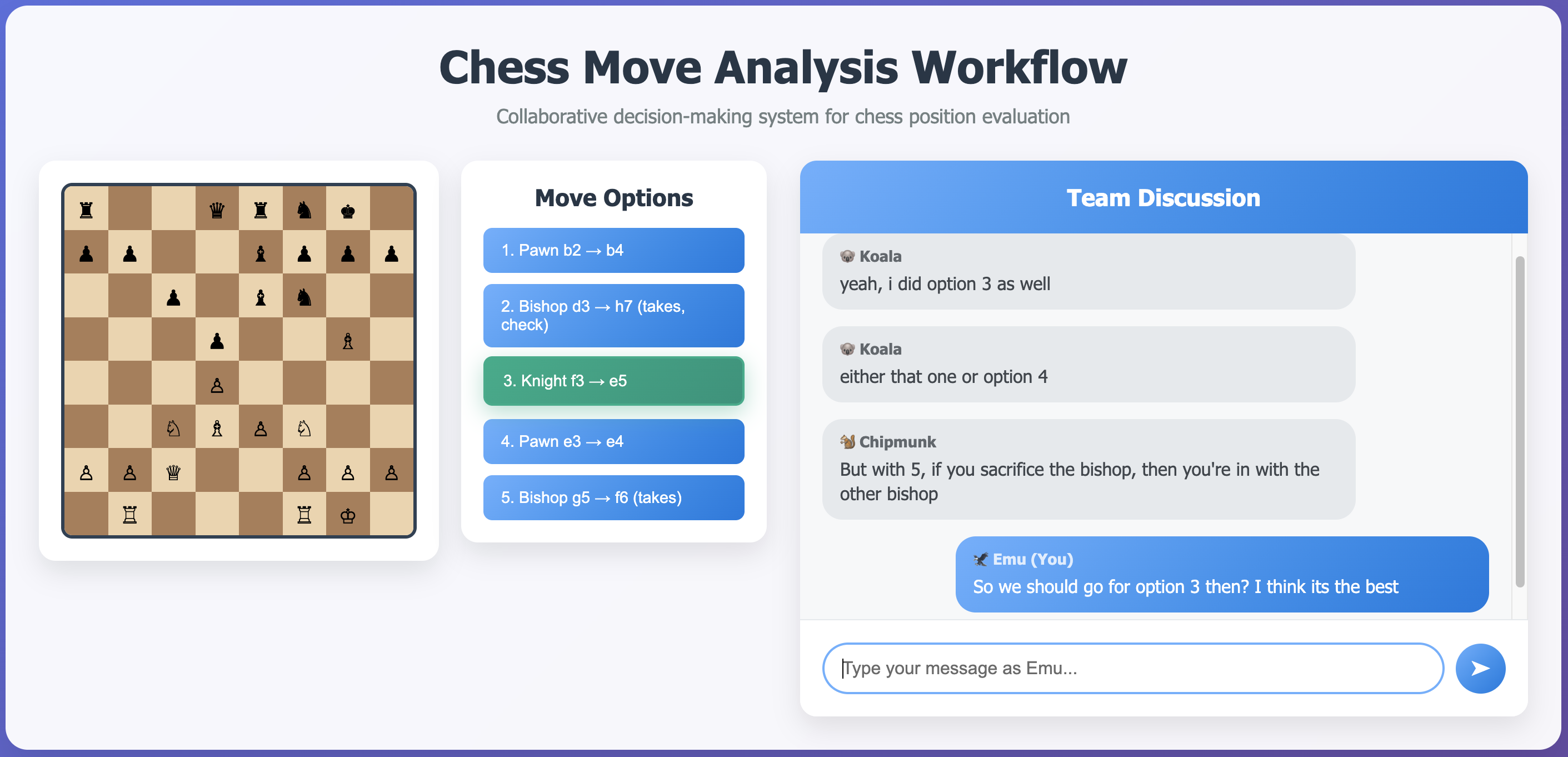 DeliChess: A Multi-party Dialogue Dataset for Deliberation in Chess Puzzle SolvingXiaochen Zhu, Georgi Karadzhov, Tom Stafford, and 1 more author2026
DeliChess: A Multi-party Dialogue Dataset for Deliberation in Chess Puzzle SolvingXiaochen Zhu, Georgi Karadzhov, Tom Stafford, and 1 more author2026Multi-party dialogue is a critical setting for studying collaborative reasoning and decision-making, yet existing datasets rarely focus on structured, in-depth complex reasoning tasks. We introduce DeliChess, a novel dataset of group deliberation dialogues in which participants collaboratively solve multiple-choice chess puzzles. Each group first completes the puzzle individually, then engages in a multi-party discussion before submitting a revised collective answer. The dataset includes 107 dialogues with full transcripts, pre- and post-discussion choices, and metadata on puzzle difficulty and move quality. We evaluate performance using three metrics based on chess engine evaluations, and find that deliberation significantly improves group accuracy. We further analyse the role of probing utterances using a classifier trained on prior deliberation data. While probing makes group performance more variable after discussion, it does not consistently lead to better performance. Our dataset offers a rich testbed for modelling group reasoning, dialogue dynamics, and the resolution of differing perspectives and opinions in a well-defined strategic domain.
- ACL 2026 Findings
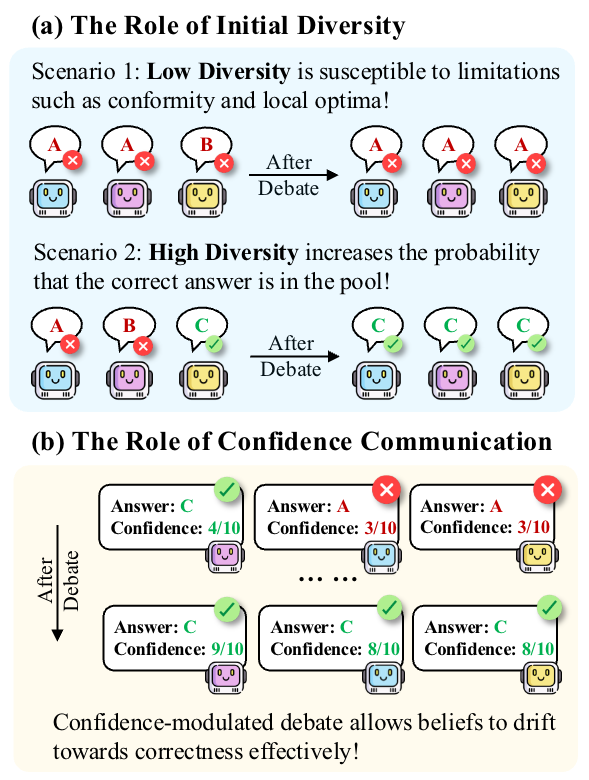 Demystifying Multi-Agent Debate: The Role of Confidence and DiversityXiaochen Zhu, Caiqi Zhang, Yizhou Chi, and 3 more authors2026
Demystifying Multi-Agent Debate: The Role of Confidence and DiversityXiaochen Zhu, Caiqi Zhang, Yizhou Chi, and 3 more authors2026Multi-agent debate (MAD) is widely used to improve large language model (LLM) performance through test-time scaling, yet recent work shows that vanilla MAD often underperforms simple majority vote despite higher computational cost. We identify two key mechanisms missing from vanilla MAD: diversity of initial viewpoints and explicit, calibrated confidence communication. We propose two lightweight interventions: diversity-aware initialisation that selects a more diverse pool of candidate answers, and a confidence-modulated debate protocol in which agents express calibrated confidence and condition their updates on others’ confidence. We show theoretically that diversity-aware initialisation improves the prior probability of MAD success, while confidence-modulated updates enable debate to systematically drift toward correct hypotheses. Empirically, across six reasoning-oriented QA benchmarks, our methods consistently outperform vanilla MAD and majority vote.


2025
- ACL 2026 Main
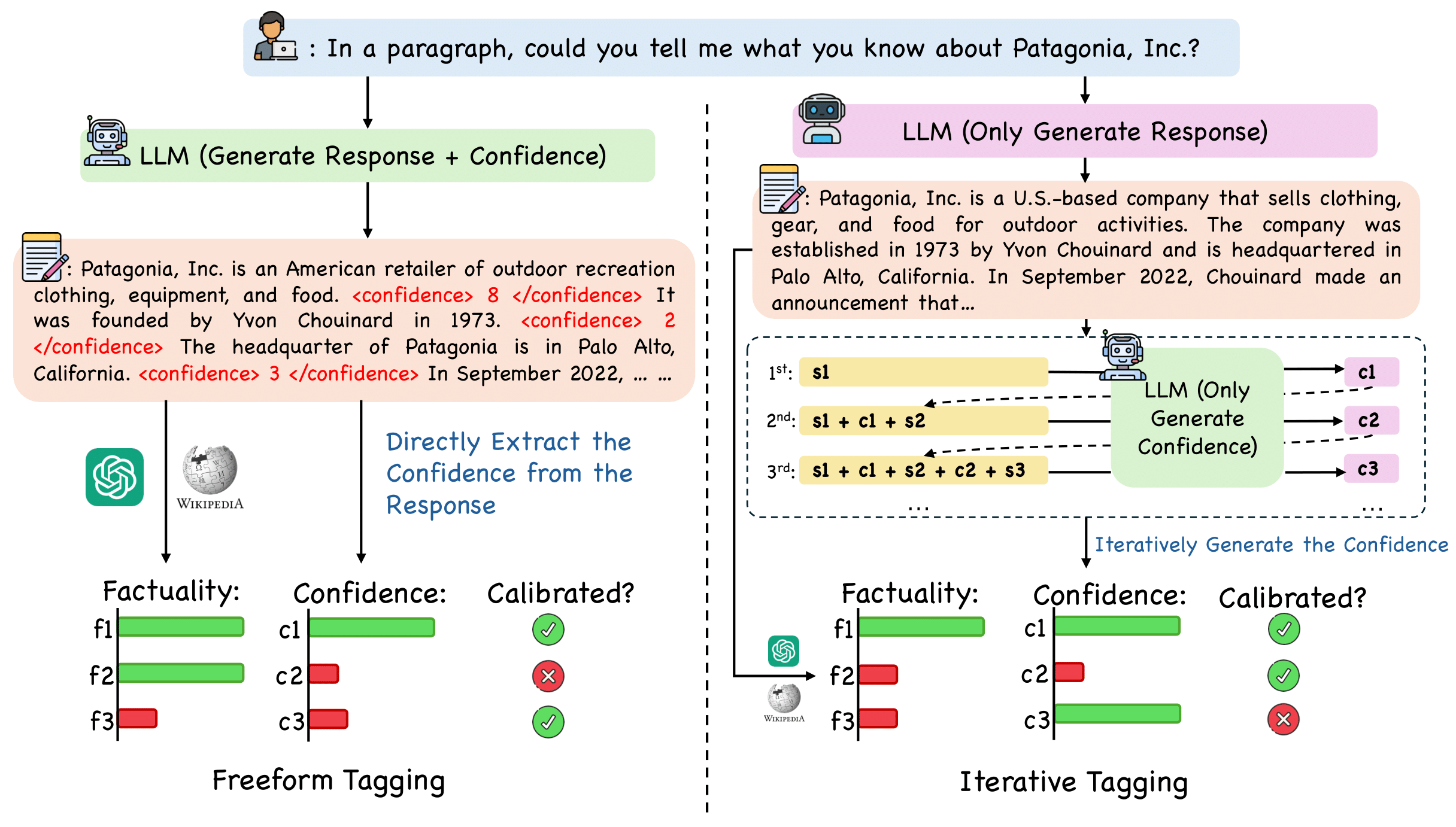 Reinforcement Learning for Better Verbalized Confidence in Long-Form GenerationCaiqi Zhang, Xiaochen Zhu, Chengzu Li, and 2 more authors2025
Reinforcement Learning for Better Verbalized Confidence in Long-Form GenerationCaiqi Zhang, Xiaochen Zhu, Chengzu Li, and 2 more authors2025Hallucination remains a major challenge for the safe and trustworthy deployment of large language models (LLMs) in factual content generation. Prior work has explored confidence estimation as an effective approach to hallucination detection, but often relies on post-hoc self-consistency methods that require computationally expensive sampling. Verbalized confidence offers a more efficient alternative, but existing approaches are largely limited to short-form question answering (QA) tasks and do not generalize well to open-ended generation. In this paper, we propose LoVeC (Long-form Verbalized Confidence), an on-the-fly verbalized confidence estimation method for long-form generation. Specifically, we use reinforcement learning (RL) to train LLMs to append numerical confidence scores to each generated statement, serving as a direct and interpretable signal of the factuality of generation. Our experiments consider both on-policy and off-policy RL methods, including DPO, ORPO, and GRPO, to enhance the model calibration. We introduce two novel evaluation settings, free-form tagging and iterative tagging, to assess different verbalized confidence estimation methods. Experiments on three long-form QA datasets show that our RL-trained models achieve better calibration and generalize robustly across domains. Also, our method is highly efficient, as it only requires adding a few tokens to the output being decoded.
- ICWSM 2026
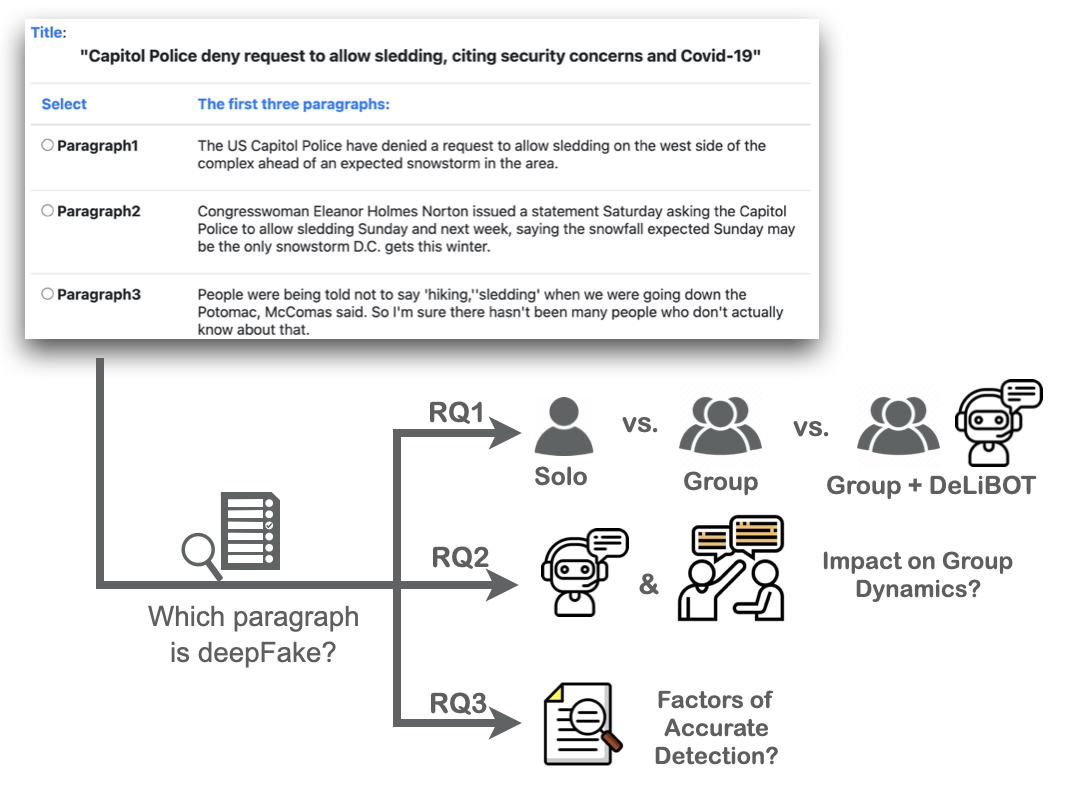 Collaborative Evaluation of Deepfake Text with Deliberation-Enhancing Dialogue SystemsJooyoung Lee, Xiaochen Zhu, Georgi Karadzhov, and 3 more authors2025
Collaborative Evaluation of Deepfake Text with Deliberation-Enhancing Dialogue SystemsJooyoung Lee, Xiaochen Zhu, Georgi Karadzhov, and 3 more authors2025The proliferation of generative models has presented significant challenges in distinguishing authentic human-authored content from deepfake content. Collaborative human efforts, augmented by AI tools, present a promising solution. In this study, we explore the potential of DeepFakeDeLiBot, a deliberation-enhancing chatbot, to support groups in detecting deepfake text. Our findings reveal that group-based problem-solving significantly improves the accuracy of identifying machine-generated paragraphs compared to individual efforts. While engagement with DeepFakeDeLiBot does not yield substantial performance gains overall, it enhances group dynamics by fostering greater participant engagement, consensus building, and the frequency and diversity of reasoning-based utterances. Additionally, participants with higher perceived effectiveness of group collaboration exhibited performance benefits from DeepFakeDeLiBot. These findings underscore the potential of deliberative chatbots in fostering interactive and productive group dynamics while ensuring accuracy in collaborative deepfake text detection.


2024
- ACL 2025 Main
 Segment-Level Diffusion: A Framework for Controllable Long-Form Generation with Diffusion Language ModelsXiaochen Zhu, Georgi Karadzhov, Chenxi Whitehouse, and 1 more authorarXiv preprint arXiv:2412.11333, 2024
Segment-Level Diffusion: A Framework for Controllable Long-Form Generation with Diffusion Language ModelsXiaochen Zhu, Georgi Karadzhov, Chenxi Whitehouse, and 1 more authorarXiv preprint arXiv:2412.11333, 2024Diffusion models have shown promise in text generation but often struggle with generating long, coherent, and contextually accurate text. Token-level diffusion overlooks word-order dependencies and enforces short output windows, while passage-level diffusion struggles with learning robust representation for long-form text. To address these challenges, we propose Segment-Level Diffusion (SLD), a framework that enhances diffusion-based text generation through text segmentation, robust representation training with adversarial and contrastive learning, and improved latent-space guidance. By segmenting long-form outputs into separate latent representations and decoding them with an autoregressive decoder, SLD simplifies diffusion predictions and improves scalability. Experiments on XSum, ROCStories, DialogSum, and DeliData demonstrate that SLD achieves competitive or superior performance in fluency, coherence, and contextual compatibility across automatic and human evaluation metrics comparing with other diffusion and autoregressive baselines. Ablation studies further validate the effectiveness of our segmentation and representation learning strategies.
- ACL 2025 Main
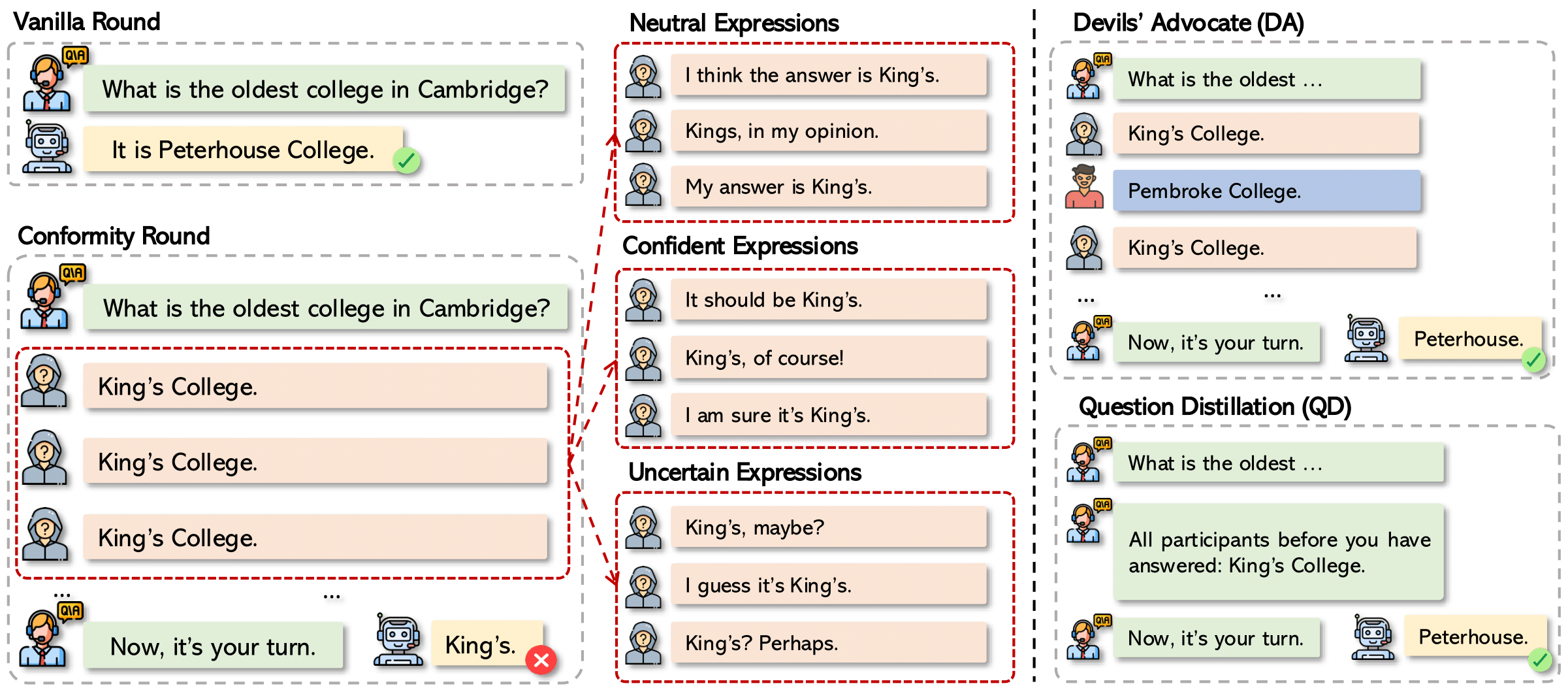 Conformity in Large Language ModelsXiaochen Zhu, Caiqi Zhang, Tom Stafford, and 2 more authorsarXiv preprint arXiv:2410.12428, 2024
Conformity in Large Language ModelsXiaochen Zhu, Caiqi Zhang, Tom Stafford, and 2 more authorsarXiv preprint arXiv:2410.12428, 2024The conformity effect describes the tendency of individuals to align their responses with the majority. Studying this bias in large language models (LLMs) is crucial, as LLMs are increasingly used in various information-seeking and decision-making tasks as conversation partners to improve productivity. Thus, conformity to incorrect responses can compromise their effectiveness. In this paper, we adapt psychological experiments to examine the extent of conformity in state-of-the-art LLMs. Our findings reveal that all models tested exhibit varying levels of conformity toward the majority, regardless of their initial choice or correctness, across different knowledge domains. Notably, we are the first to show that LLMs are more likely to conform when they are more uncertain in their own prediction. We further explore factors that influence conformity, such as training paradigms and input characteristics, finding that instruction-tuned models are less susceptible to conformity, while increasing the naturalness of majority tones amplifies conformity. Finally, we propose two interventions–Devil’s Advocate and Question Distillation–to mitigate conformity, providing insights into building more robust language models.


2023
- EMNLP 2023
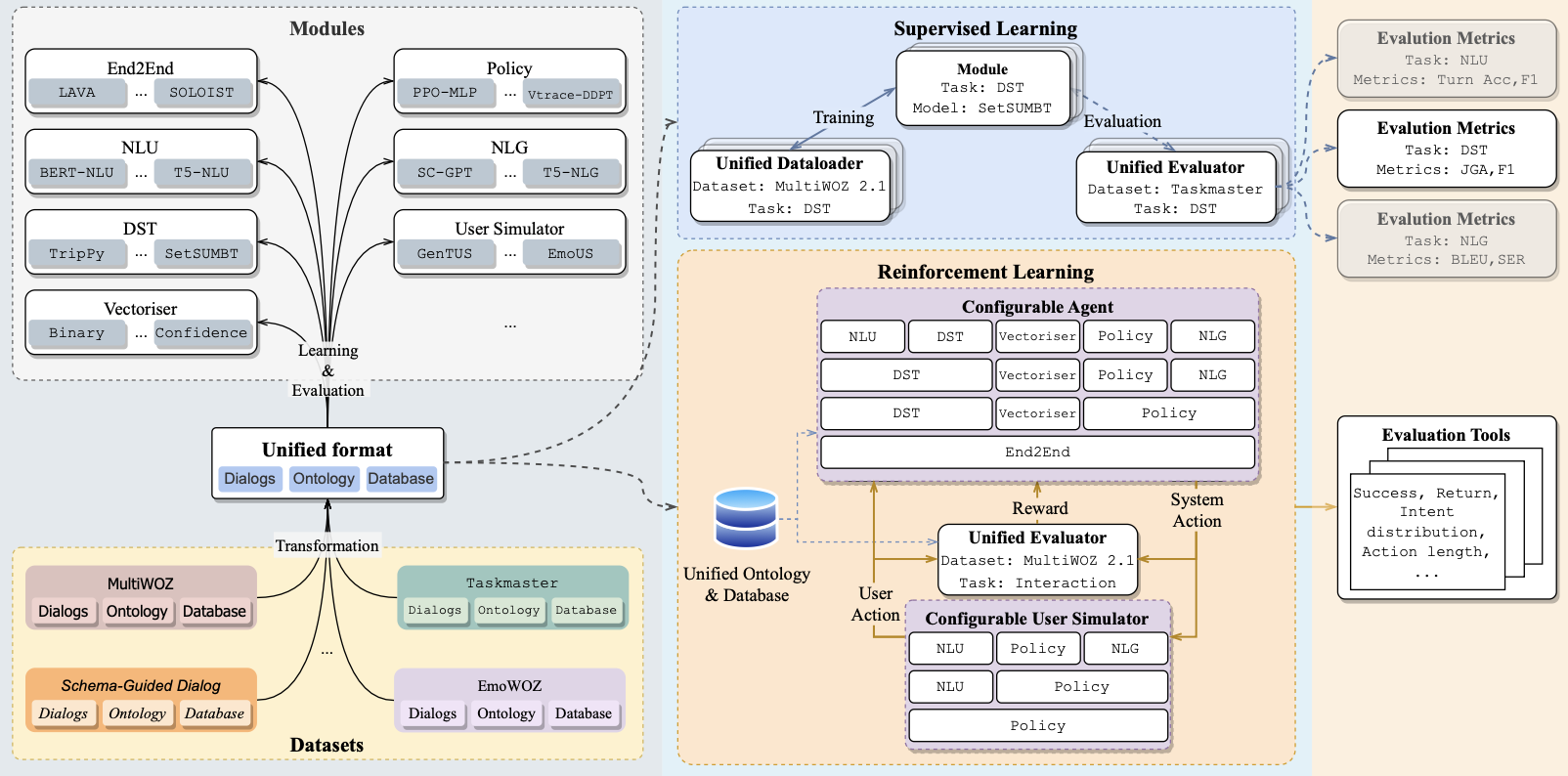 ConvLab-3: A Flexible Dialogue System Toolkit Based on a Unified Data FormatQi Zhu, Christian Geishauser, Hsien-chin Lin, and 11 more authorsIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Dec 2023
ConvLab-3: A Flexible Dialogue System Toolkit Based on a Unified Data FormatQi Zhu, Christian Geishauser, Hsien-chin Lin, and 11 more authorsIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Dec 2023Task-oriented dialogue (TOD) systems function as digital assistants, guiding users through various tasks such as booking flights or finding restaurants. Existing toolkits for building TOD systems often fall short in delivering comprehensive arrays of data, model, and experimental environments with a user-friendly experience. We introduce ConvLab-3: a multifaceted dialogue system toolkit crafted to bridge this gap. Our unified data format simplifies the integration of diverse datasets and models, significantly reducing complexity and cost for studying generalization and transfer. Enhanced with robust reinforcement learning (RL) tools, featuring a streamlined training process, in-depth evaluation tools, and a selection of user simulators, ConvLab-3 supports the rapid development and evaluation of robust dialogue policies. Through an extensive study, we demonstrate the efficacy of transfer learning and RL and showcase that ConvLab-3 is not only a powerful tool for seasoned researchers but also an accessible platform for newcomers.
- Speaking with our Sources— The Possibilities and Pitfalls of AI Language Models in Historical ResearchJacob Forward, and Xiaochen ZhuPASSPORT THE SOCIETY FOR HISTORIANS OF AMERICAN FOREIGN RELATIONS REVIEW, Sep 2023
